TensorStore: Google's Open-Source C++ And Python Library for High-Performance, Scalable Array Storage
This open-source C++ and Python library is intended for reading and writing large multi-dimensional arrays.


Working with massive multi-dimensional data arrays is fairly common for machine learning engineers and data scientists, especially on large-scale projects. Because large amounts of data require time and storage, working with it efficiently is essential for a streamlined workflow.
In light of this, Google AI has released TensorStore, an open-source Python and C++ software library designed to store and manipulate n-dimensional data.
TensorStore
TensorStore, as mentioned briefly in the above section, is an open-source Python and C++ software library designed to store and manipulate n-dimensional data. This module supports a wide range of storage systems, including local and network filesystems, Google Cloud Storage, and so on. It provides a consistent API for reading and writing various array types. The library provides read/writeback caching, transactions, and a guarantee of atomicity, isolation, consistency, and durability (ACID). Optimistic concurrency ensures secure access to various programs and systems.
Use Case
Language Models
TensorStore application cases include PaLM and other advanced big language models. These neural networks, with their hundreds of billions of parameters, push the boundaries of computing infrastructure while demonstrating unexpected ability in producing and understanding plain language.
Accuracy in reading and writing the model parameters poses a challenge during the training process. Despite the fact that training is distributed across multiple workstations, parameters must be stored on a long-term storage system on a regular to avoid causing the training process to lag.

TensorStore has already been used to address these challenges. This framework, which has been integrated with frameworks like T5X and Pathways, has been used to link large-scale (multipod) models trained in JAX to checkpoints.
Brain Mapping
One application for TensorStore that Google researchers suggested is brain mapping, which involves creating a detailed schematic of the function of various areas of the brain. To handle petabyte-size datasets, such a use case necessitates large storage and processing capabilities.
The h01 dataset, one of the largest datasets for data on human brain tissue, was handled by Google's team using TensorStore. h01 contains approximately 1.4 petabytes of imaging data that users can manipulate with TensorStore.
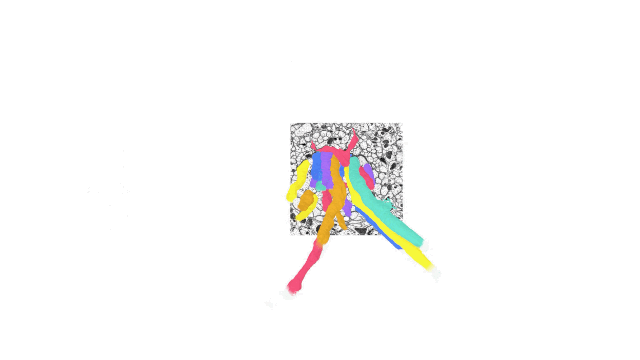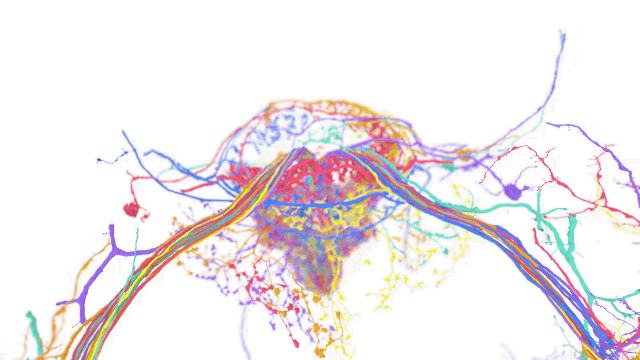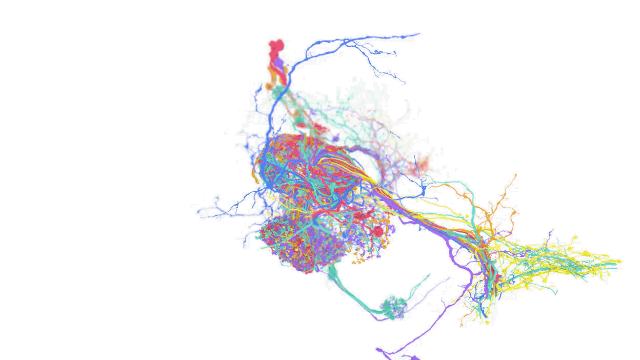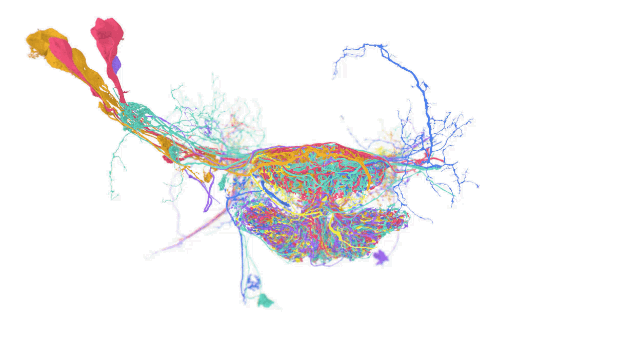
The newly released AI tool can also support indexing features such as alignment and virtual views through down sampling and data type conversion.
Useful Resources
- GitHub: https://github.com/google/tensorstore
- Google Blog: https://ai.googleblog.com/2022/09/tensorstore-for-high-performance.html
- Tutorial: https://google.github.io/tensorstore/python/tutorial.html
- API documentation: https://google.github.io/tensorstore/python/api/index.html
- Installation: https://google.github.io/tensorstore/installation.html
Conclusion
That's all, folks! I hope you learned about TensorStore.
Please share if you found this article useful. Feel free to respond if you have any thoughts, feedback, or comments.
Until next time, happy coding and learning! Cheers!
About the author
Paula Isabel Signo is a technical writer at OSSPH and a web developer at Point One. In her free time, Paula contributes to various open-source projects, volunteers in the community, and shares her knowledge by writing articles and tutorials. Connect with Paula here to learn more about her work and interests.